Character sets
Molly pages are written and saved in some character set.
These pages are then saved in some encoding when saved to
disk. These encodings are typically 7-bit US-ASCII (128 characters),
ISO-8859-1 (256 characters), UTF-8 (any of the millions of
unicode characters), UTF-16/32 (ditto) and so on.
(See UTF-Note below)
Molly pages are then translated to Java source files. These source
files are then compiled into executable java code (class files) and
then the output is sent to the browser.
The Java compiler translates unicode escapes (\uXXXX) to
equivalent unicode characters. This allows one to use plain old
ascii to write java programs and still use unicode codepoints in
the program (typically in java Strings and chars, read the java
language specification for exact details on unicode escapes).
One can also directly embed unicode characters in Java programs and
save the java program as, say, a UTF-8 encoded file on disk. When
compiling this UTF-8 java-source file, one can say: javac -encoding UTF-8 program.java.
Either way, once the program is compiled, the resulting .class file can
contain arbitrary unicode characters (either from the unicode escape or
the direct character that you typed).
The java program can send these unicode characters to a web browser.
These unicode characters are sent out in some arbitrary encoding
(such as UTF-8, UTF-16, UTF-32 etc.) and this encoding has no
relation to how these unicode characters were typed into the java
program in the first place.
When sending these characters to the browser, the browser needs
to know the actual encoding used in the output. This is done
via setting the charset in the Content-Type HTTP header.
If you are new to all this, character encodings is a pretty simple concept
but can appear a bit tricky. There are several good tutorials
on the web that you can search for. (For example, as of this
writing, see this
for a good overview).
Molly pages
Several possibilities arise when writing a molly page.
These are shown below.
For illustrative purposes, I use the character 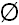 . This
corresponds to codepoint 216 (decimal) or D8 (hex) of unicode and looks like
a circle with a line drawn through it. In the examples below,
if you see this character as-is in the browser, that's good. If you
see a question mark instead, that means something is amiss.
. This
corresponds to codepoint 216 (decimal) or D8 (hex) of unicode and looks like
a circle with a line drawn through it. In the examples below,
if you see this character as-is in the browser, that's good. If you
see a question mark instead, that means something is amiss.
Case #1
[page encoding=UTF-8] (src-encoding not necessary) -or-
[page src-encoding=ISO-8859-1 encoding=UTF-8] (but you can always specify it)
|
In Browser, with HTTP Content-Type set to: |
.mp file (mollypage)
encoding: ISO-8859-1 |
Translated to .java (java sourcefile written in ISO-8859-1) |
Compiled to .class
(javac -encoding ISO-8859-1) |
ISO-8859-1 |
UTF-8 |
Text_section
(plain text) |
\u00D8 |
out.println("\\u00D8"); |
will send 5 ascii characters to the browser (exactly what was typed)
\ u 0 0 D 8 |
\u00D8 |
\u00D8 |
Code_section
(java code): |
[[
out.println("\u00D8");
]] |
out.println("\u00D8"); |
Will send one character (unicode 216) to the browser
|
? |
|
The page is written in ISO-8859-1 or US-ASCII using Java unicode
escape sequences to send unicode characters to the browser.
Case #2
[page src-encoding=UTF-8 encoding=UTF-8]
|
In Browser, with HTTP Content-Type set to: |
.mp file (mollypage)
encoding: UTF-8 |
Translated to .java (java sourcefile written in UTF-8) |
Compiled to .class
(javac -encoding UTF-8) |
ISO-8859-1 |
UTF-8 |
Text_section
(plain text) |
|
out.println(""); |
Will send one character (unicode 216) to the browser (exactly what was typed)
|
? |
|
Code_section
(java code): |
[[
out.println("");
]] |
out.println(""); |
Will send one character (unicode 216) to the browser
|
? |
|
Arbitrary Unicode characters are directly typed in the page. This makes
is easier to visualize/edit these characters because you do not have
to worry about hacking unicode escape sequences.
Note: since the source contains UTF-8 characters, if you do not specify
src-encoding=UTF-8, you may get compiler errrors. If the source is not
ISO-8859-1 or ASCII, always specify the src-encoding.
In this example, one can also specify
[page src-encoding=UTF-8 encoding=IS0-8859-1]
This will compile properly but wont display properly (the browser
will typically show ? instead of rending the character)
Note: One can also run the native2ascii tool that comes with
the JDK. This allows one to type unicode directly and then convert
the file containing arbitrary unicode characters into a file
containing only ascii text (and java unicode escapes). After doing this,
the situation is somewhat similar to case (1) above. This is not
recommended because it adds an extra (unnecessary) step to
writing/publishing a page (it's easier to use the src-encoding
directive.)
Case #3
|
In Browser, with HTTP Content-Type set to: |
.mp file (mollypage)
encoding: ISO-8859-1 |
Translated to .java (java sourcefile written in ISO-8859-1) |
Compiled to .class
(javac -encoding ISO-8859-1) |
ISO-8859-1 |
UTF-8 |
Text_section
(plain text) |
Ø |
out.println("Ø"); |
Will send 6 characters to the browser (exactly what was typed)
& # 0 2 1 6; |
|
|
Code_section
(java code): |
[[
out.println("Ø");
]] |
out.println("Ø"); |
Will send 6 characters to the browser
& # 0 2 1 6; |
|
|
There is no need to specify either the src-encoding or encoding (both
default to UTF-8). Note, since we are using HTML unicode
entities, the HTML charset does NOT have to be UTF-8 (the characters
will still be rendered properly with IS0-8859-1).
Recommendations
- Use HTML unicode escapes for the simplest possible situation. No
encoding for anything has to be specified this way.
- Type Unicode characters directly and specify both the encoding and
src-encoding to be the same value. Use UTF-8 as it is the simplest.
(and
UTF-8 is now the default with newer versions of mollypages anyway, just make sure
your text editor is savings your source files as UTF-8).
- Do not use Java unicode escapes. They are too complicated to keep
track of across different levels of source, class and output.
UTF NOTE:
UTF-8 is a great, simple efficient encoding for any arbitrary unicode
character (properly: codepoint). UTF-8 is independent of byte
order, so DO NOT use the BOM (byte order mark). Note, javac
(as of version 1.5) will crash if you use BOM. Use UTF-8, NO-BOM.
 /
License & Download /
Tutorials /
Cookbook
/
License & Download /
Tutorials /
Cookbook
 /
Contact & Hire
/
Contact & Hire